
Let’s Build the Lovable AI Agent [Tutorial+Code]
We'll see how the agent works and build our own.

Lovable reached $400M ARR in just 14 mos. That kind of growth attracts two types of people: people who want to use it, and engineers who want to understand how it actually works. This post is for the 2nd group — you and me!
In this article, we’re going to understand (from sources including Lovable and Anthropic’s tech blogs) how the AI agent with $6.6B valuation is built. This is part #1 of my new series where I’m going to break down the design and implementation of AI agents we all know and love :) Let’s go —
Some background:
You already know that Lovable is, at its core, a coding agent. You describe something in natural language, and the agent writes React code, provisions a Postgres database, deploys edge functions, wires up auth, runs browser tests, and gives you a live URL — all without you touching a terminal. Understanding how that agent is designed tells you a lot about how to build ANY prod-grade agent in general.
The Lovable team made a long series of deliberate, empirically-validated engineering decisions — and many of them run counter to what the AI community was promoting at the time! They tried complex multi-agent orchestration and abandoned it. They found that bigger context windows hurt quality. They built a two-stage retrieval system before that was a common pattern. They treat verification as a core loop, not an add-on. We’ll go through the architecture layer by layer, with code to show how the key components can be assembled. Where design decisions were made deliberately by the Lovable team, I’ll say why — because the “why” is where the real engineering lives :)
Before we start:
The full Python code for the AI agent we’re designing (and the future ones too) is here:
https://github.com/sarthakrastogi/design-ai-agent/tree/main/lovable
If you’d like to reach out to me, here’s my LinkedIn:
https://www.linkedin.com/in/sarthakrastogi/
Features of the AI agent:
Before diving into architecture, here’s everything the Lovable agent does:
Two-mode execution: Plan mode (reasoning, no code changes) and Agent mode (autonomous execution with full tool access)
Codebase-aware context gathering: searches and reads only relevant files before generating edits, instead of blindly feeding the whole repo
Multi-file coordinated edits: applies changes across frontend, backend, and configuration in a single pass
Supabase orchestration: generates schema, RLS policies, auth flows, and deploys edge functions from natural language
Browser-based verification: spins up a headless browser in a remote sandbox to click through flows and capture screenshots for self-verification
Frontend unit tests: writes and runs Vitest + React Testing Library tests to lock in UI behavior
Edge function testing: calls Supabase edge functions directly, inspects request/response, writes Deno-native regression tests
Web search during generation: fetches documentation or assets in real time when needed to complete a task
Automatic secret detection: blocks hardcoded API keys (~1,200/day!!) and redirects them to server-side secret storage
GitHub two-way sync: every agent edit commits to GitHub; pushes from the IDE sync back to Lovable
Prompt queue: users can queue follow-up prompts while the agent is running; queue is reorderable, pauseable, and repeatable up to 50 times
Persistent knowledge and skills: workspace-level instructions always injected into context; on-demand skill playbooks loaded selectively per request
Cross-project referencing: agent can read code, files, assets, and chat history from other projects in the same workspace
Execution visibility: every step of agent execution is surfaced to the user in a Details view: files being modified, tools being called, progress through multi-step builds
Usage-based pricing per agent run: cost scales with files modified, tools used, and codebase exploration depth
What’s in the Agent
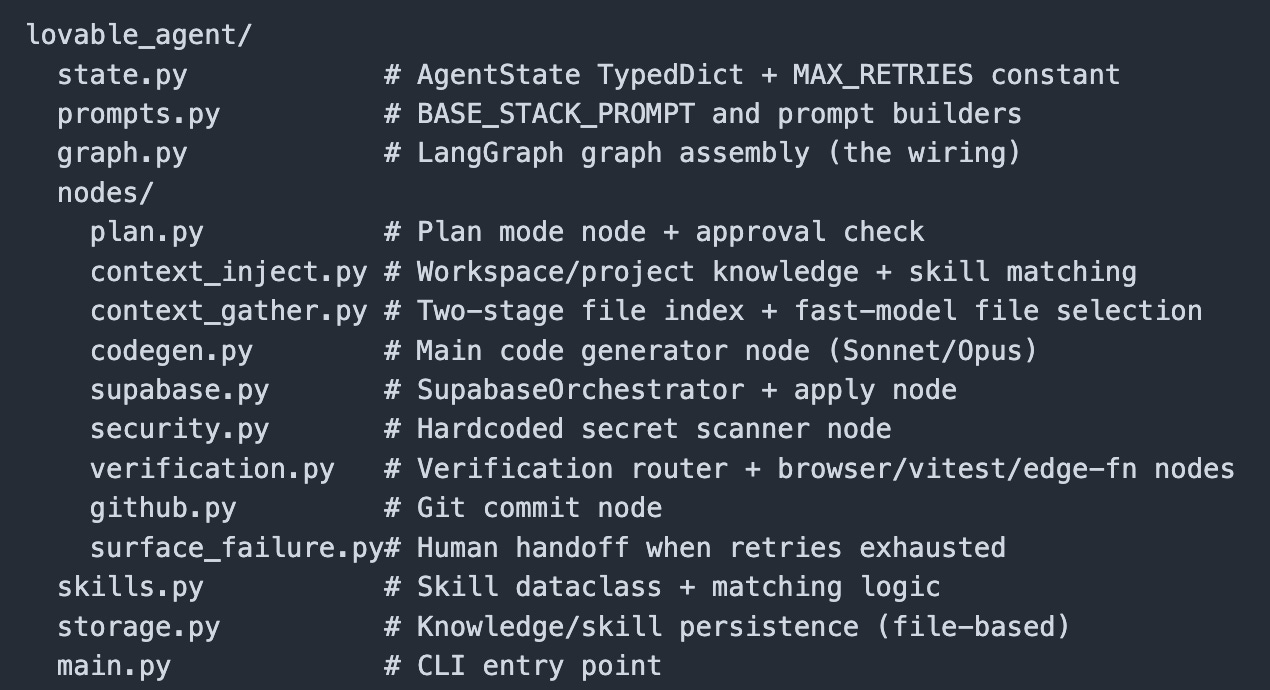
Here’s a quick at how the code for our AI agent is structured. All of these components will get clearer as we go.
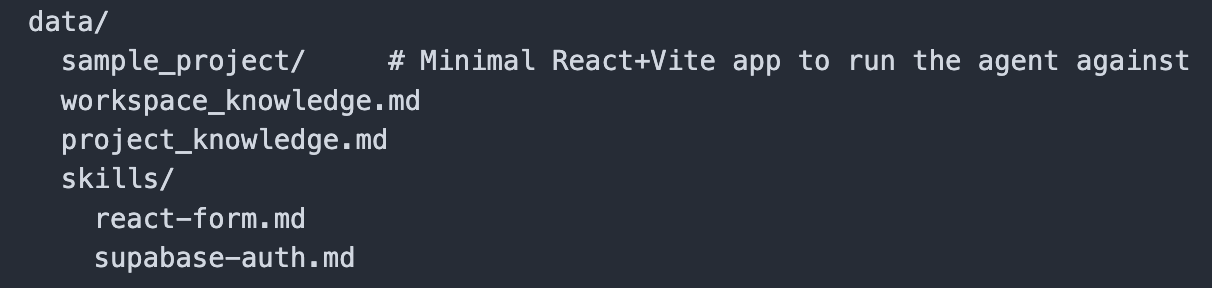
In the repo there’s also tests, skills/instructions, and a starter app to work with:
Okay, let’s get into the agent now:
Two Modes, One Agent
The first decision in the AI agent’s structure — splitting execution into two distinct modes: Plan mode and Agent mode — 2 states of the same agent. They work together and switch at any time.
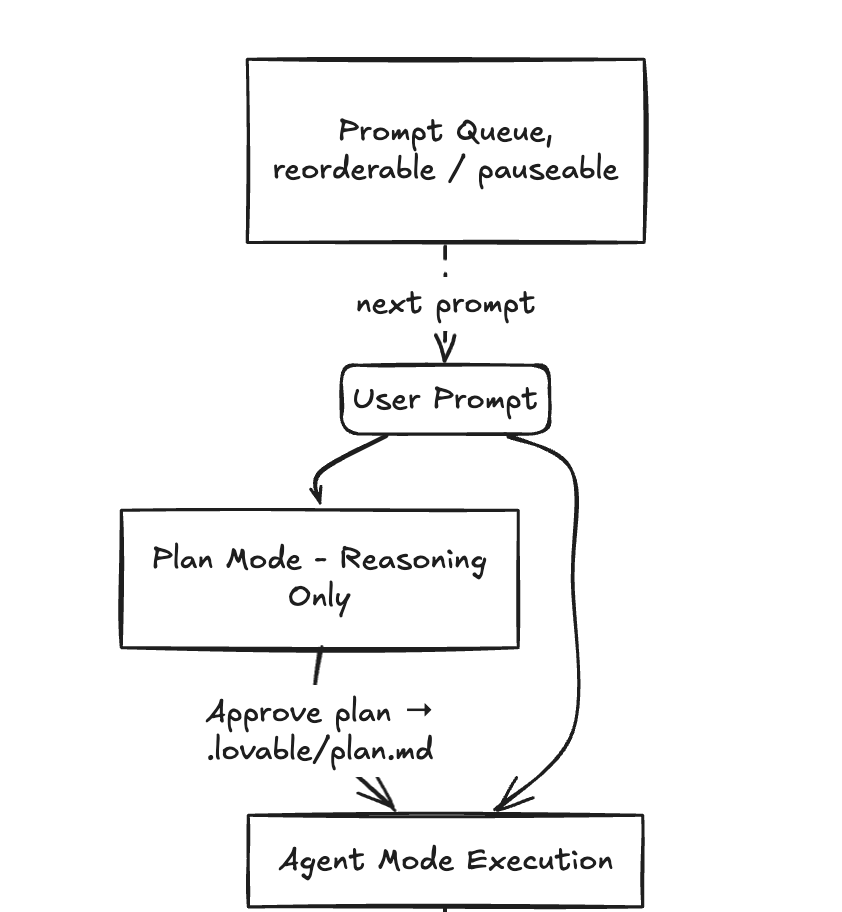
Plan mode is for decision-making — thinking through problems, exploring options, and deciding on an approach. It never modifies code. It can reason across multiple steps and inspect files, logs, or other relevant project context as needed. Plan mode often asks clarifying questions to better understand goals and constraints before proposing anything. Every message in Plan mode costs 1 credit.
Agent mode is for execution. When you give Lovable a task in Agent mode, it takes ownership end to end — it understands your intent, explores the codebase for context, applies changes across files, and resolves issues that appear during development. The two modes are designed to work together, and you can switch between them at any time.
This split matters architecturally because it maps to two fundamentally different LLM call patterns. Plan mode is a conversational loop: the LLM reasons, asks questions, generates a plan document, and waits for approval. Agent mode is a ReAct-style execution loop: reason —> act —> observe —> repeat, with real tools at each step.
When there is a clear implementation to propose in Plan mode, Lovable creates a formal plan — saved to .lovable/plan.md — that includes:
a high-level overview
key decisions, assumptions and constraints
components, data models, APIs
step-by-step implementation sequencing
Plans can include optional diagrams such as schemas, flows, or architecture. You can edit the plan directly as MD before approving it. When you approve, Lovable switches to Agent mode and implementation begins based strictly on that approved plan.
The reason for this split is user trust as much as it is architecture. When users don’t understand what the agent is about to do, they hesitate to let it run. When it fails and they don’t know why, they lose confidence in the whole system. A plan gives users a checkpoint to course-correct before tokens are spent on execution — and a written record of what was supposed to happen when something goes wrong.
Here’s how you’d model this dual-mode structure in LangGraph. The state type is central: it carries everything the agent needs across the entire run, from the initial prompt through verification:

The plan_approved field is how the human stays in the loop. In Lovable’s UI it’s a button — “Approve plan.” In your own agent it could be a webhook, a message, or a CLI prompt. The important thing is that the graph waits at that edge until the human signals yes.
Context Injection
Before the AI agent generates a single line of code, it assembles context. This is the most deterministic part of the pipeline!
When you send a message, Lovable reads project + workspace knowledge, and project code to understand how the project works before generating edits. It also looks at integration knowledge from connected services and instruction files in the repository — AGENTS.md or CLAUDE.md are both read automatically.
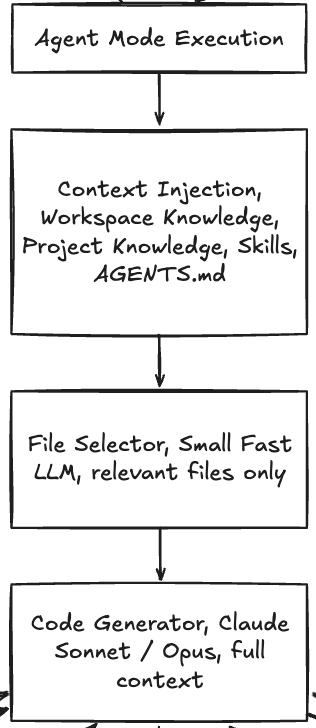
Lovable has three layers of persistent context, each with different scope and loading behavior:
Workspace knowledge: rules that apply to every project in a workspace. Coding standards, preferred libraries, naming conventions, brand voice. This is always injected into context, on every call, no exceptions. It supports up to 10,000 chars.
Project knowledge: context specific to one project: the application purpose, database schema, architecture decisions, domain terminology, external API references. Also always injected. If workspace and project knowledge conflict, project knowledge wins — it’s more specific to the current context.
Skills: named, MD-based playbooks loaded on demand with a name+description that tells Lovable when to use it, and instructions Lovable follows when activated. Skills are not included in every call — they’re retrieved by matching the current request against each skill’s description. This keeps the base prompt lean. You invoke them explicitly with
/skill-namein the chat, or Lovable matches them automatically. Root-levelAGENTS.mdfiles are always read regardless of session length — they’re the closest thing Lovable has to persistent, repo-level agent configuration.
Do note here the distinction between always-on context and on-demand context. Always-on context (workspace knowledge, project knowledge) defines the invariants — things that should be true for every generation. On-demand context (skills) is injected only when the task warrants it. This matters because LLMs perform worse with irrelevant context, and loading your entire playbook into every call wastes tokens and dilutes focus.
Here’s the full context injection node, including skill matching:

Notice that match_skills_to_request uses the cheapest available model — Claude Haiku 4.7. It’s a routing call. Its job is to answer one simple question: is this skill relevant?
This is a pattern throughout Lovable’s architecture: use the cheapest model that can reliably solve the subproblem.
Intelligent File Selection
Lovable uses a fast, cheap model to pre-select which files are relevant before calling the main generation model. Of course, this is better than using the whole codebase because LLMs become effectively less capable (in a non-linear way!!) when looking at too many things at once. It’s not just about token cost savings — we want the model to only attend to things it should. And ONLY make changes to files it should touch.
The architecture follows a “hydration” pattern — a fast pre-pass prepares and selects relevant context, then the selected context is handed to the larger model for the main generation. So our agent should be able to search your codebase to locate the exact files, functions, or components needed; and aslo read files on demand to understand the app’s structure and apply edits with full context.
This is a two-stage retrieval system.
Stage one: build a lightweight index of the project (file paths, exports, brief summaries) and use a fast model to select the relevant subset.
Stage two: read only the selected files in full and pass their content to the main model.
There’s also a subtlety in the max_files cap. Setting a ceiling forces the selector to prioritize. If every file in the project seems vaguely relevant, that’s a signal the request is too broad — and the cap will catch it before the main model call :)
Constraining the Output Space
Unlike general-purpose assistants like Cursor or GitHub Copilot that must work with any lang or framework, Lovable constrains the solution space to optimize for reliability:
React 18 with TypeScript strict mode
Tailwind CSS for styling
shadcn/ui for component primitives
React Query for server state
Zustand for client state
Vite as the build tool.
The stack is not negotiable — and that’s the point.
This is a deep agent design principle worth internalizing: constrain the output space. An agent that can generate anything generates inconsistent things. An agent that always outputs React + TypeScript + Tailwind + shadcn can be tuned, evaluated, and improved against a stable target. The model’s generation becomes significantly more deterministic. The evals harness is easier to build. The prompts are easier to write. The error patterns are known and fixable. The opinionation lets the team continuously fine-tune their system to work extremely well within these specific constraints.
Here’s what the system prompt skeleton looks like. Note the structured JSON output requirement — this is load-bearing:

The structured JSON output makes multi-file edits reliable. If you ask an LLM to return prose with code blocks and then parse them, you get inconsistent delimiters, ambiguous paths, and truncated files. A schema-validated JSON response is deterministic. And critically, the output schema is designed around what the orchestration layer needs: it tells the system exactly which files to write, which SQL to run, and which edge functions to deploy — all in one response.
The Code Generator — Prompt Structure and LLM Selection
Lovable uses Claude Sonnet for most generation tasks and Opus for more complex multi-file refactors. Opus and Sonnet’s 1M context window handle the primary reasoning and code generation capacity. The model selection is dynamic: simple requests with fewer files use Sonnet; complex requests with large context windows or architectural changes use Opus.
Here’s the code generator node. You wanna see how the selected file contents + assembled system prompt + the conversation history are all composed into the final messages array:

The error_context field deserves special attention. When the verification loop fails — browser tests crash, Vitest reports failures, edge function returns 500 — the error details are stuffed back into error_context and the state is routed back to this node. The node then includes a “Previous Attempt Failed” block in the user message. The model sees what it tried, what broke, and what the failure looked like. This is the self-correction mechanism, and it’s why agent mode reduced build error rates by 90% compared to the single-shot default mode.
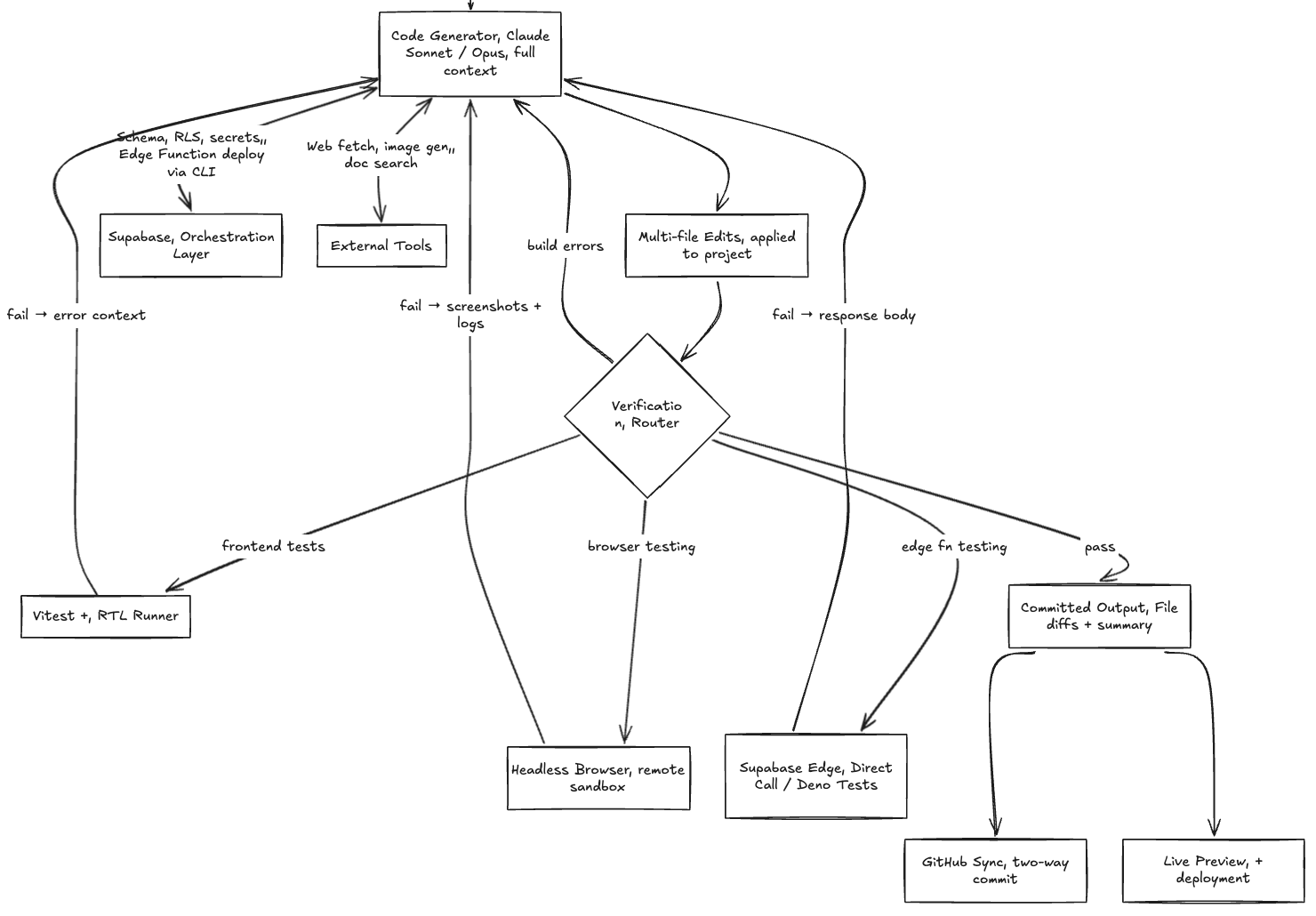
Supabase Orchestration — Being the Infrastructure Layer
Working with LLMs, context is everything. The key to making AI agents useful is providing them with the right info at the right time. To understand a backend, you need: database schema (tables, relationships, and structure), secrets and API keys, and logs and errors to debug issues automatically. The Supabase API exposed almost everything needed to provide this context dynamically.
The security model that emerged from this is explicit and enforced at the agent level. The anon (publishable) key lives in the browser and is safe to expose — it can only perform operations that RLS policies allow. The service role key lives exclusively in Edge Functions via Cloud Secrets, never in client-side code. Lovable enforces this separation automatically and blocks approximately 1,200 hardcoded API keys per day from making it into application code.
When Supabase is connected, the agent’s context gains a live view of the database. The agent can read your existing table schema, understand your current RLS policies, and generate code that correctly targets your specific project — including writing migrations that don’t conflict with existing tables.
The Verification Loop for Self-Correction
A coding agent that only writes code is a prototype. A production agent verifies what it wrote, observes the result, and corrects itself. Lovable has three distinct verification mechanisms: browser testing, frontend tests, and edge function verification. Verification reduces build error rates by 90% compared to the single-shot default mode.
Browser Testing
Browser testing lets Lovable interact with the app in a real browser running in a virtual environment. The agent can click buttons, fill forms, navigate pages, and verify real user behavior with screenshots instead of relying on code alone. The agent can capture screenshots, click buttons and links, fill inputs and submit forms, navigate between pages, read console logs and network requests, detect runtime errors, and test different screen sizes including mobile, tablet, and desktop.
Browser testing is triggered by explicit phrases: “verify it works”, “test this”, “check if it’s working”, “make sure it works.” It is slower than other verification methods because it’s interacting with a real browser, so Lovable uses it selectively.
Note that the browser runs in a remote secure sandbox, and any authenticated requests use the same session the user is currently logged into in the preview.
Frontend Tests (Vitest + React Testing Library)
Frontend tests verify UI behavior in isolation using clear assertions. They run in a simulated browser environment (jsdom), give consistent results, and usually live next to components as .test.tsx files. The test stack is Vitest, React Testing Library, and jsdom.
These are the right tool when you want a specific rule locked in: form validation catches invalid email formats, cart state updates on click, error messages render on network failure. They run fast and give the agent precise, structured failure signals.
Edge Function Testing
Direct calls let the agent run an edge function with specific inputs and inspect the request/response immediately. This avoids UI-related complexity and is useful for quick isolation when the bug is suspected to be in backend logic. Edge tests are automated tests that check backend rules over time using the Deno built-in test runner with native TypeScript support.
A common debugging sequence: call the edge function directly to reproduce the issue with a specific input. Apply the fix. Call the function again with the same input to confirm the change. Add an edge test to ensure the behavior does not regress. This sequence keeps iteration fast while still providing long-term verification.
Of course, we don’t want a systematic bug to loop the agent indefinitely, so after MAX_RETRIES attempts, the agent stops, surfaces what it tried, and asks the user for guidance.
Prompt Engineering at Scale
Prompt engineering in production is about building a regression harness.
The team starts simple and iteratively adds complexity only when necessary. When prompts are modified to address edge cases, the team conducts extensive back-testing against a library of previous queries to ensure improvements don’t introduce regressions in other areas. The workflow looks like this:
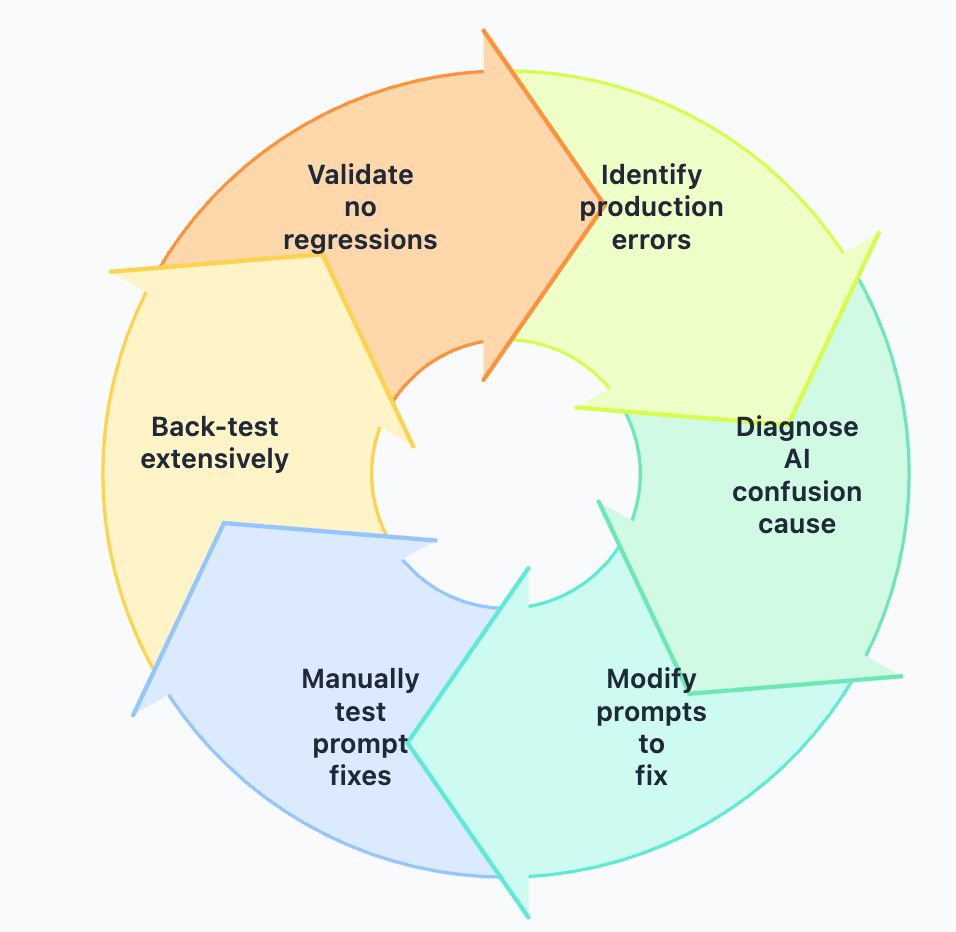
This is a CI/CD pipeline for prompts! For your own agent, this means you need a prompt evaluation dataset before you have a prompt worth deploying. The Lovable team’s competitive moat is their evaluation infrastructure built up over thousands of production interactions.
One concrete technique they mention: “teach the models without fine-tuning.” — rather than fine-tuning on proprietary data (which they have done in the past but don’t use as the core flow), via examples, negative constraints, and explicit decision rules.
GitHub Integration as Agent Memory
Every agent edit in Lovable creates a Git commit — agent memory is implemented at the VCS layer.
Commits are atomic — the agent never writes a half-applied change.
They’re reversible — one undo button and you’re back to the previous commit.
They’re semantic — each commit message describes what the agent did.

The commit message format matters. agent: <summary> as the prefix means you can filter agent commits in git log trivially. The modified files list in the body gives reviewers an instant diff summary. This is the kind of small, deliberate choice that makes an agent’s output legible to humans working alongside it.
Prompt Queue for Concurrency
Lovable processes one task at a time. While the agent is working, you can continue sending prompts and they will be added to a visible queue. You can pause and resume the entire queue as needed, reorder, edit, copy, or remove individual queued prompts, and repeat a queued prompt a specified number of times — up to 50.
With a queue, you can batch related work, reorder when priorities change, and set up repetitive runs (e.g., “try fixing this bug 3 times and show me the best result”).
The repeat-up-to-50 feature is practically interesting. It turns the agent into a Monte Carlo sampler over code quality — run the same prompt multiple times, review the outputs, keep the best one. This is particularly useful for UI generation tasks where “best” is somewhat subjective and the distribution of outputs is wide.
For your own agent, the queue also functions as an explicit task manager. Each item in the queue is a unit of work with a defined scope. Keeping tasks small and queued is better than sending one giant multi-task prompt — the agent handles focused requests more reliably than sprawling ones.
Why They Rejected Complex Multi-Agent Architectures
This is the most instructive part of Lovable’s engineering story, and it directly contradicts what was being promoted in the AI community at the same time they were making this decision.
Their previous approach involved sophisticated multi-agent systems (MAS) with agents communicating with each other, similar to Devin, etc. They found three systematic problems:
First, lower accuracy — the complex systems failed more often than simpler approaches.
Second, user confusion — when failures occurred, users had no understanding of what went wrong, making the system effectively unusable even when the failure rate was acceptable.
Third, slower performance — users would wait minutes only to encounter failures, creating a compounding trust problem.
The platform prioritizes speed and reliability over complex agent architectures. Their current approach is as fast and as simple for the user to understand what’s going on as possible.
The lesson isn’t “never use multi-agent systems.” The lesson is more nuanced: multi-agent complexity has a production cost that shows up in non-obvious ways. Cascading failures become hard to attribute. Latency compounds — since each sequential agent call adds overhead. User trust erodes when the system fails in ways they can’t reason about. And debugging becomes exponentially harder when failure could have originated anywhere in a chain of agent calls.
The “multi-agent” complexity Lovable does use is scoped and controlled: a cheap model for routing and file selection, a powerful model for generation, and deterministic verification tools that aren’t LLM calls at all. The intelligence is concentrated at the generation step. Everything else is either a cheap routing call or a deterministic program.
Security as a Core Agent Behavior
To prevent sensitive credentials from being exposed, Lovable automatically detects API keys pasted into the chat and guides storage in Secrets instead of hardcoding in code. When you describe an integration, Lovable generates the implementation using server-side Edge Functions and secure secret storage — keeping credentials out of the browser entirely. Edge Functions are JWT-protected by default.
Lovable uses four automated security scanners covering core vulnerability categories:
RLS Analysis (reviews database access policies and row-level security rules)
Code scanning
Auth flow analysis
Dependency scanning.
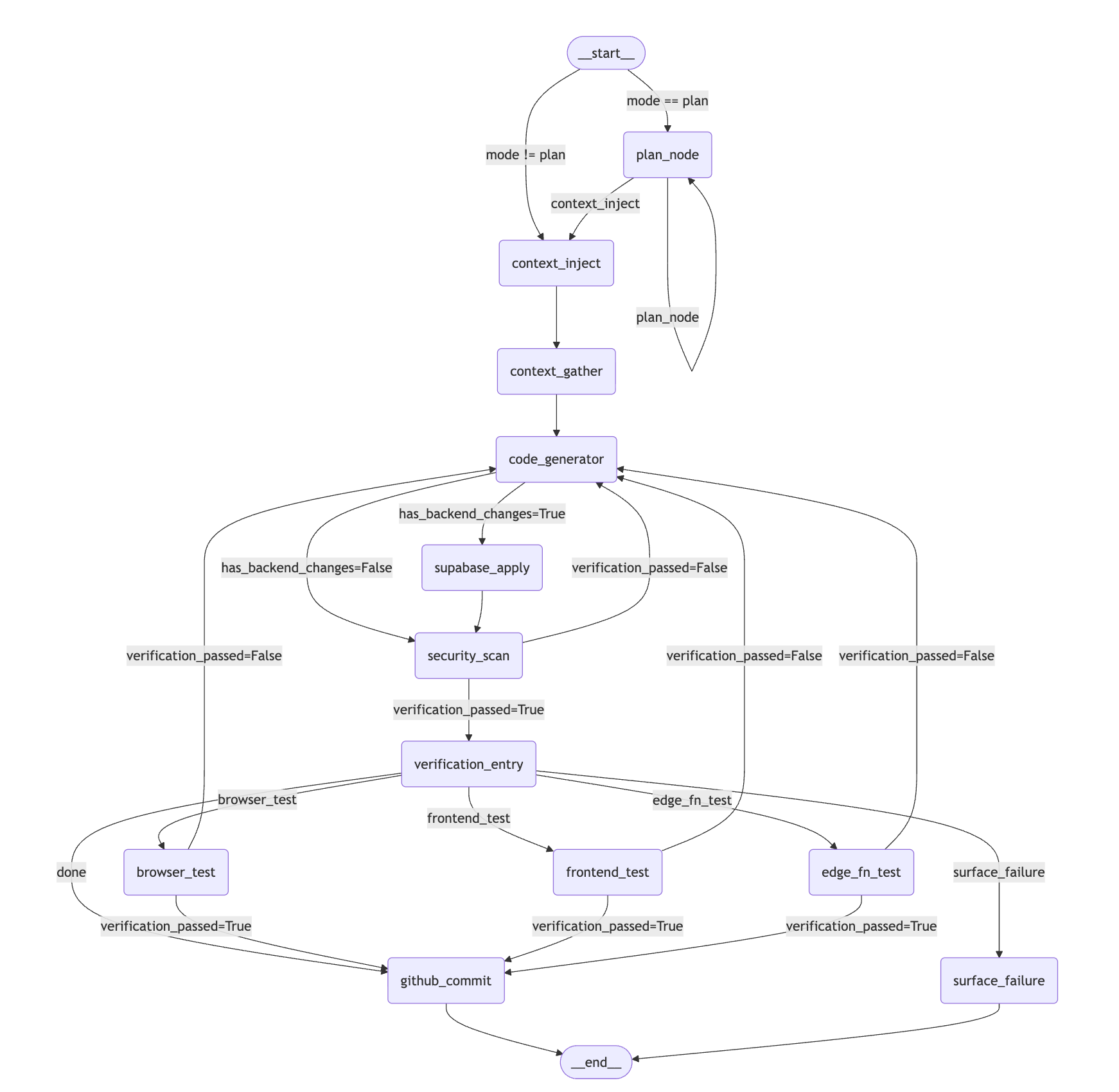
Putting It All Together — The Complete Graph
Here’s the full LangGraph flow, incorporating every component:

The code’s output graph:
Key Engineering Takeaways
The patterns in Lovable’s architecture aren’t specific to app-building agents. They apply to any agent that takes actions in the real world.
Constrain the output space early. Lovable’s opinionated stack makes the agent reliable at scale. The more unconstrained the output space, the harder it is to evaluate, test, prompt-tune, and improve. Pick a target and get very good at hitting it.
Context selection is not a nice-to-have. Using a fast model to pre-filter context before the main generation call is one of the most impactful architectural decisions Lovable made. More context is not always better context. The performance degradation from irrelevant context is real and non-linear.
Two-stage retrieval beats one-shot context stuffing. Build a lightweight index, route with a cheap model, read only what’s relevant. This applies beyond code agents — any agent that reads from a large corpus benefits from this pattern.
Verification belongs in the agent loop, not after it. The error signal from a failed test is more actionable than any human description of the same problem. Design your verification layer first; build the generator to produce output that can be verified.
Security constraints go in the core loop. Secret detection, RLS enforcement, service key isolation — these need to be baked into the system prompt and enforced by a dedicated scan pass. They cannot be afterthoughts bolted on after the agent is “working.”
Two-mode design improves user trust. Separating planning (no side effects) from execution (real changes) gives users a checkpoint. When agents take real-world actions — writing files, running migrations, deploying functions — users need to understand what’s about to happen before it happens.
Git is a better memory layer than custom state. If your agent modifies files, commit to a VCS. You get atomicity, reversibility, semantic history, and compatibility with every developer tool for free.
Simplicity scales better than cleverness. Lovable tried complex multi-agent orchestration and abandoned it. The current architecture — cheap model for routing, powerful model for generation, deterministic verification — is simpler, faster, and more reliable. The intelligence is concentrated where it matters most.
Build the evaluation harness before optimizing prompts. Prompt engineering at production scale is a regression testing problem. Every prompt change needs to be validated against a library of historical queries. Without this, you’re flying blind — improvements in one area silently break another.
Thank you for reading :)
The full Python code for the AI agent we’re designing (and the future ones too) is here:
https://github.com/sarthakrastogi/design-ai-agent/tree/main/lovable
If you’d like to reach out to me, here’s my LinkedIn:
https://www.linkedin.com/in/sarthakrastogi/
You can also directly schedule a call with me here:
https://topmate.io/sarthakrastogi
For more of my AI agents, see
https://liten.tech/ and https://www.miskies.app/