
Improve Your RAG Accuracy With A Smarter Chunking Strategy
Here's how to pick a good one based on your data + use case.

Bad chunking is like taking a well-organised filing cabinet and dumping everything on the floor, then wondering why you can’t find anything.
😐
Everyone obsesses over which embedding model to use. Or which vector database has the lowest latency. Or prompt engineering their retrieval queries to perfection.
But your RAG system is probably failing because of how you’re chunking your documents. Chunking is arguably the most important decision you’ll make, and it’s the one easiest to get wrong.
I’ve seen teams spend weeks fine-tuning embedding models, only to get mediocre results because they’re using fixed-size chunking that splits sentences mid-thought. It’s like having a Ferrari with flat tires.
How to Use This Article
If you’re building a RAG system right now: Skip to the section matching your document type (financial, medical, technical, etc.) and implement those strategies immediately.
If you’re debugging poor RAG performance: Start with “Why Most Chunking Strategies Are Awful” to diagnose the issue, then jump to solutions.
If you’re optimizing an existing system: Focus on “Scaling to 10K+ Documents” and the evaluation metrics section.
If you’re just learning about RAG: Read straight through. The examples will make everything clear.
Table of Contents
Why Most Chunking Strategies Are Awful
The Three Types of Chunking Strategies
Layout-Aware Chunking: The Game Changer
Advanced Strategies That Actually Work
Domain-Specific Playbooks
See interactive visualisation for this topic
Financial Documents
Medical Records
Legal Contracts
Technical Manuals
Handling Tables and Images
Scaling to 10K+ Documents in prod
How to Actually Evaluate Your Chunking Strategy
The Decision Framework
Why Most Chunking Strategies Are Awful
Let me show you what bad chunking looks like in practice.
You have a financial report. There’s a table showing quarterly revenue. Right after the table, there’s a paragraph explaining why Q3 revenue dropped 15%. Your chunking strategy splits them into separate chunks.
Someone asks: “Why did Q3 revenue decline?”
Your RAG system retrieves the table. But not the explanation. The LLM hallucinates an answer based on the numbers alone. Wrong answer. User loses trust.
This isn’t a theoretical problem. This happens constantly in production RAG systems.
Here’s another one: You’re chunking a legal contract with fixed 512-token windows. A clause about liability spans 650 tokens. Your chunker splits it right in the middle. The first chunk says “The company is liable for...” and the second chunk starts with “...except in cases of this and that.”
Guess which chunk gets retrieved when someone asks about liability? Yeah, the first one. Without the exception. Legal team is not happy.
Or this: You’re processing medical records with recursive character chunking. A patient’s medication list is followed by critical warnings about drug interactions. They get split. Someone queries about prescribing that medication. The warning never shows up. That’s a patient safety issue.
The problem isn’t your embedding model. It’s that you’re feeding it garbage.
The Three Red Flags of Bad Chunking
Red Flag #1: Context loss at boundaries
You’re reading along, everything makes sense, then suddenly the chunk ends mid-sentence. The next chunk starts with “However, this approach...”
This approach? What approach?? The LLM has no idea because the previous context is gone.
Red Flag #2: Tables without full context (or incomplete tables)
Incomplete tables are useless. While it’s not hard to make sure that tables are treated as individual chunks (and not split up), there’s another problem.
Tables without their context are useless. You’ll see RAG systems retrieve tables that are perfectly formatted, completely accurate, and utterly meaningless because nobody knows what the table is measuring.
“Here’s a table with numbers” is not helpful. “Here’s Q3 revenue by region, showing the 15% decline mentioned in the CEO’s statement” is helpful.
Red Flag #3: List item issues
Similarly you’ll see chunking split a list so that only the first chunk has the list header. Now you have five chunks that say:
“Item 1: Something about compliance”
“Item 2: Something about auditing”
“Item 3: Something about reporting”
Something about WHAT? Compliance with what? The header that explained this was a “Data Protection Checklist” is in a different chunk.
Why This Happens
Suppose we start with the simplest possible approach: fixed-size chunking. Split the text every 512 tokens. Done.
It’s fast. It’s simple. It’s predictable.
It’s also terrible.
Fixed-size chunking doesn’t know what a sentence is. It doesn’t know what a paragraph is. It certainly doesn’t know what a table is. It just counts to 512 and cuts.
Then we can get slightly more sophisticated and try recursive character splitting. “I’ll split on paragraph breaks, then line breaks, then spaces!”
Better. But still not very helpful cus your document has structure that you’re completely ignoring.
Your documents weren’t randomly generated. Someone organised them deliberately.
There are headers that tell you what each section is about. There are tables that group related information. There are lists that enumerate steps or requirements.
All of that structure? We need to respect it. But fixed-size and recursive chunking throw it away.
It’s like taking a well-organised filing cabinet and dumping everything on the floor, then wondering why you can’t find anything.
The Three Types of Chunking Strategies
Not all chunking strategies are created equal. Here’s how they break down:
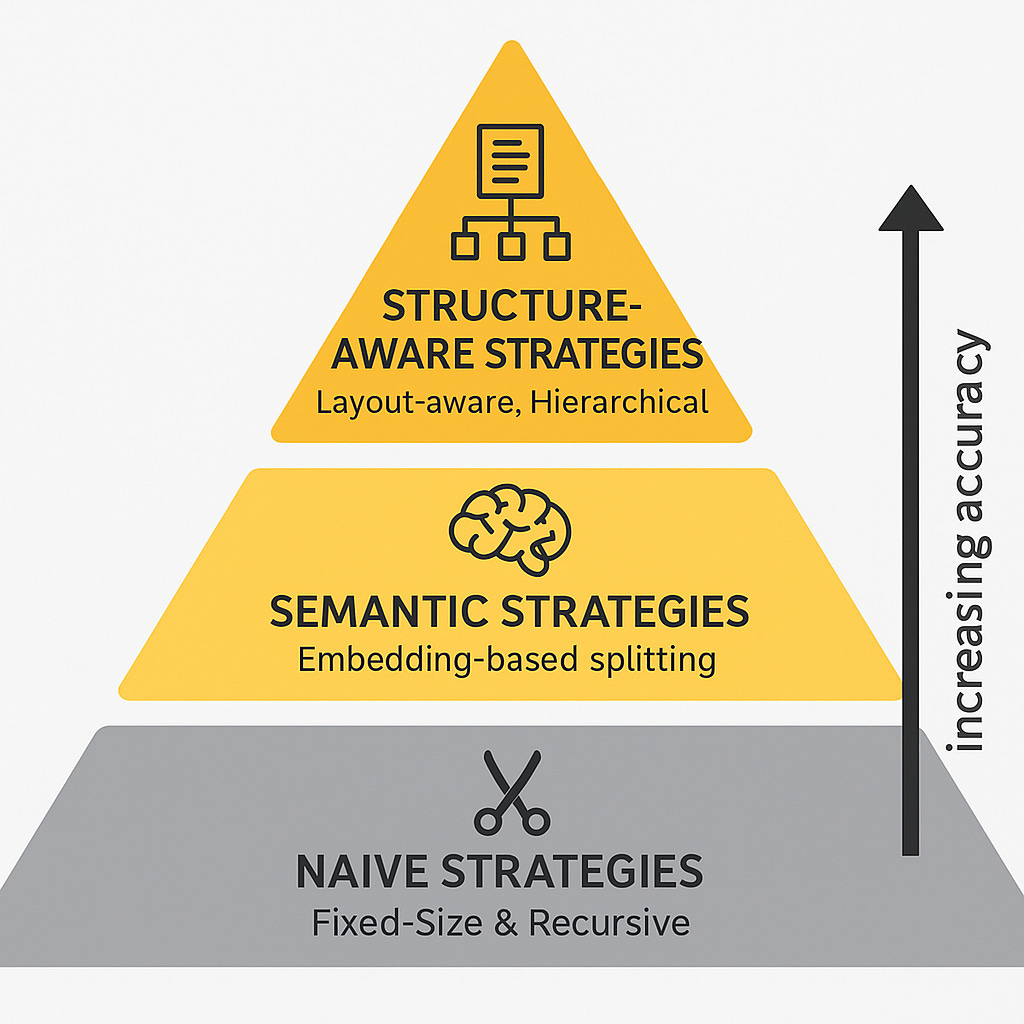
Naive Strategies (The Baseline You Should Move Past)
Fixed-Size Chunking: Split every N tokens. Fast, simple, and loses all context.
Use case: You need a quick prototype or you’re working with genuinely unstructured text (chat logs, social media feeds). That’s it.
Recursive Character Chunking: Split on
\n\n, then\n, then spaces. Slightly respects structure.Use case: Mixed document types where you need something better than fixed-size but don’t want complexity.
These are your training wheels. They’re fine for learning. Not fine for production.
Semantic Strategies (Getting a Lilll Bit Better)
Semantic Chunking: Use embeddings to detect topic shifts. Split when the semantic distance between sentences >= a threshold.
This is where things get interesting. Instead of blindly counting tokens, you’re actually looking at what the text means. When the topic changes, you split.
Research shows semantic chunking significantly outperforms naive approaches. It preserves coherent topics within chunks, which means better retrieval accuracy.
The catch is that it requires running an embedding model on every sentence, calculating distances, and tuning thresholds. More compute, more complexity, but much better results.
When to use it: Complex documents where topic boundaries matter more than structural boundaries. Academic papers, long-form articles, research reports.
Structure-Aware Strategies (The Good Stuff)
This is where you should be spending your time.
The Core Insight: Documents already have structure. Use it.
Here’s what works really well:
Recognising that a document has headers, and those headers tell you what the following paragraphs are about.
Recognizing that a table is a self-contained unit.
Recognizing that a list is a list.
And so on.
Layout-Aware Chunking
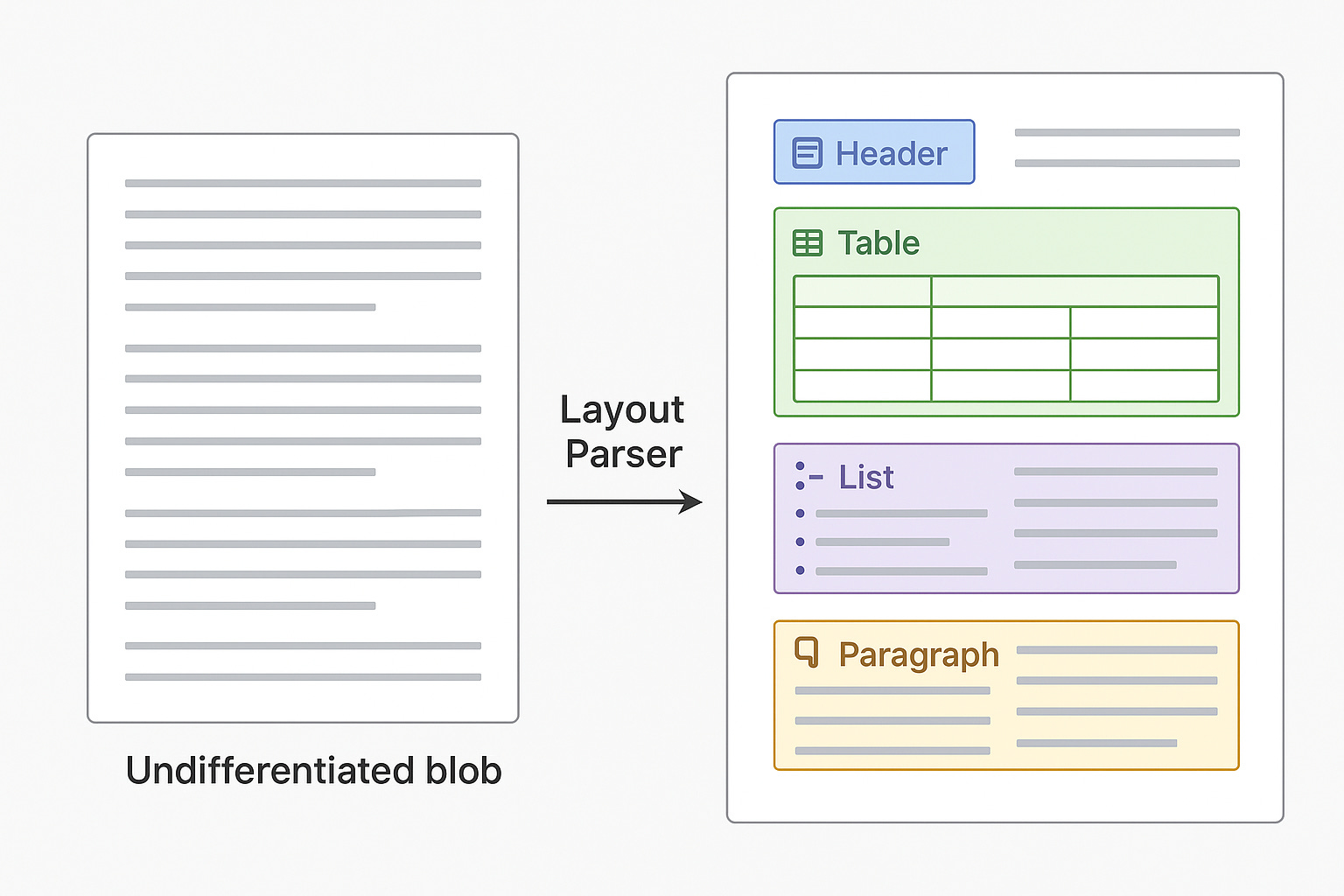
Humans don’t read documents as flat text streams. We use visual cues.
When you open a PDF, you immediately see:
The title (big, bold, top of page)
Section headers (medium, bold, with spacing)
Paragraphs (blocks of regular text)
Tables (grid structure, distinct from text)
Lists (bullets or numbers, indented)
Figures (images with captions)
You use all of this to understand the document. Why shouldn’t your RAG system?
Layout-aware chunking means parsing documents with their structure intact. You identify titles, headers, sections, tables, lists, and figures. Then you chunk intelligently around those boundaries.
How It Actually Works
Let’s walk through a real example. You have a 10K financial filing.
Traditional approach:
Split every 512 tokens
Get 847 chunks
Pray for good retrieval
Layout-aware approach:
1. Parse document and identify structure
- 42 section headers detected
- 18 tables detected
- 127 subsections detected
2. Create hierarchical chunks
- Each table = separate chunk (with header preserved)
- Each subsection = separate chunk (with section header added)
- Each list = chunked by items (with list title added)
3. Add metadata
- section_id: “financial_statements.income_statement”
- parent_section: “financial_statements”
- chapter: “annual_results”
- page_number: 47
Now when someone asks about Q3 revenue, you don’t just retrieve a random chunk. You retrieve the income statement section, with full context about what you’re looking at.
Three Principles of Layout-Aware Chunking
Principle 1: Respect Visual Boundaries
If there’s a section header, that’s a semantic boundary. Don’t split across it unless absolutely necessary.
If there’s a table, keep it together. Don’t split it unless it’s huge (and even then, split row-by-row, not mid-row).
If there’s a list, keep related items together. Don’t separate list items from their header.
Principle 2: Preserve Context Through Metadata
Every chunk should know where it came from. What section? What chapter? What page?
This lets you implement clever retrieval patterns. Retrieve a specific chunk, but show the LLM the entire section. Or retrieve based on chunk-level precision, but expand to parent-level context when needed.
Principle 3: Handle Special Elements Specially
Tables are structured data. Extract them separately, convert to CSV or markdown, and chunk them intelligently.
Same with lists. Same with code blocks in technical docs. Same with figures.
Don’t treat everything as a flat text stream. It’s not.
The Tools That Make This Possible
You need a parser that understands document layout.
Three example options (lmk in a comment if you prefer another one)
DeepDocDetection (open source): Great for PDFs. Detects titles, headers, paragraphs, tables, figures. Free. Requires some setup.
Amazon Textract (AWS service): Production-ready. Handles complex layouts. Detects titles, headers, sub-headers, tables, figures, lists, footers, page numbers, key-value pairs. Costs money but works reliably.
Docling (preprocessing): Good for standardizing different document formats before chunking.
Advanced Strategies That Actually Work
Once you’ve got layout-aware chunking down, there are three advanced techniques worth knowing.
Hierarchical/Parent-Child Chunking
The problem: You want small chunks for precise retrieval. But you also want large chunks for context preservation.
The solution: Create both.
How it works:
Create large “parent” chunks (1000-2000 tokens) that preserve broad context
Split those into smaller “child” chunks (200-500 tokens) for precise matching
Index the child chunks for retrieval
Return the parent chunks to the LLM for generation
When someone asks a question, you match against the small, focused child chunks. But you give the LLM the large parent chunk with full context.
Best of both worlds.
Real example: Technical documentation. A section explains how to configure a database. The parent chunk is the entire “Database Configuration” section. The child chunks are individual configuration parameters.
User asks: “How do I set the connection timeout?”
You retrieve the child chunk about connection timeout (precise match). But you return the entire Database Configuration section to the LLM (full context about database settings, prerequisites, related parameters).
Result: Accurate answer with proper context.
Agentic Chunking (When Accuracy Matters More Than Speed)
This one’s expensive. But for high-value use cases, it’s worth it.
The concept: Use an LLM to decide how to chunk.
Convert sentences to standalone propositions (replace pronouns with actual references)
Have an LLM evaluate each proposition: “Does this belong in the current chunk or should I start a new one?”
Group semantically related propositions, even if they’re far apart in the document
Example transformation:
Original: “He led NASA’s Apollo 11 mission.”
Proposition: “Neil Armstrong led NASA’s Apollo 11 mission.”
Now that proposition makes sense on its own, without context from previous sentences.
The results: Reduction in incorrect assumptions. Significantly better answer completeness.
The cost: Multiple LLM calls per document. Slow. Expensive.
When to use it: Customer support knowledge bases, legal document analysis, medical literature review. Cases where getting the right answer matters more than processing speed.
Late Chunking (For Cross-References and Pronouns)
Standard approach: chunk first, embed later.
Late chunking: embed first, chunk later.
Why this matters: When you embed after chunking:
Each chunk only has context from within itself.
Pronouns become ambiguous.
Cross-references break.
Late chunking processes the entire document through the embedding model first. Every token gets embedded with full document context, then you chunk the token embeddings.
Result: Chunks maintain semantic information from the whole document. “The system” in chunk 47 still knows which system we’re talking about from chunk 2.
When to use it: Technical documentation with lots of cross-references. Academic papers that reference earlier sections. Any document where pronouns and implicit references are common.
The catch: Requires long-context embedding models (Jina AI embeddings v3, for example) and more compute upfront.
Domain-Specific Playbooks
Different document types need different approaches.
Financial Documents
The Challenge:
Tables everywhere.
Numbers that need context.
Sections that reference each other.
The Strategy: Layout-aware chunking with specialised table handling.
Step-by-step:
Use a layout parser (Textract or DeepDocDetection) to identify all structural elements
Handle tables specially:
Extract each table separately
Convert to CSV or markdown
Chunk row-by-row if the table is large
Include column headers with every chunk
Add the table title (usually the sentence or paragraph right before the table)
Preserve section hierarchy:
Income Statement is a section
Revenue by Segment is a subsection
Q3 Regional Breakdown is a sub-subsection
Store this hierarchy in metadata
Handle merged cells intelligently:
Unmerge them
Duplicate the original value into each cell
Ensures row-by-row chunking doesn’t lose information
What this solves:
Revenue questions get answered with the right context.
Financial metrics come with their explanations.
Tables don’t float around contextless.
Medical Documents
This is a very high stakes one.
The Challenge:
Chronological relationships matter a lot.
Clinical structure (SOAP notes).
Privacy considerations.
Precision when answering a question is life-or-death.
The Strategy: Semantic chunking for nuance, layout-aware for structure.
Key principles:
Preserve clinical note structure:
Subjective, Objective, Assessment, Plan stay together
But each can be a separate chunk with metadata linking them
Maintain temporal context:
Medication history with dates
Symptom progression over time
Previous visit references
Use semantic chunking for research papers:
Medical literature has subtle topic shifts
Semantic boundaries matter more than visual ones
Handle medical terminology carefully:
Keep terms with their context
Don’t split disease names or drug combinations
Maintain relationships between symptoms and diagnoses
What this solves: Treatment questions get accurate, complete information. Drug interaction warnings don’t get separated from prescriptions. Patient history maintains chronological coherence.
Legal Contracts
The Challenge:
Clauses must stay intact.
Cross-references are everywhere.
Structure is legally significant.
The Strategy: Layout-aware + sliding window overlap for safety.
Implementation:
Use layout parsing to identify clause boundaries:
Numbered sections
Lettered subsections
Indentation levels
Never split a clause:
If a clause exceeds max chunk size, keep it together anyway
Better one oversized chunk than broken legal language
Add sliding window overlap (10-20%):
Extra safety net for clauses that span boundaries
Reduces risk of missing critical “except” or “provided that” language
Preserve cross-references:
“See Section 4.2” needs to be retrievable
Store section references in metadata
Enable following references programmatically
What this solves: Liability questions get complete clauses with exceptions. Cross-references work. Legal teams don’t yell at you.
Technical Manuals
The Challenge:
Step-by-step procedures.
Diagrams with explanatory text.
Code examples.
Cross-references to other sections.
The Strategy: Layout-aware chunking with hierarchical metadata.
Implementation:
Respect document hierarchy:
Chapter → Section → Subsection → Procedure
Store all levels in metadata
Enables “give me everything about configuring X”
Keep procedures together:
Step 1, Step 2, Step 3 stay in one chunk
Or use parent-child: each step is a child, entire procedure is parent
Handle diagrams:
Use vision-language models to caption images
Store image description with surrounding text
Keep figure references intact
Preserve code blocks:
Code examples stay complete
Include comments and explanations
Link to related configuration settings
What this solves: Procedural questions get complete instructions. Diagrams and explanations stay together. Code examples are usable.
Handling Tables and Images (The Stuff That Breaks Everything)
Let’s talk about the elephant in the room: Most documents aren’t just text.
The Table Problem
Tables are structured data pretending to be text. Naive chunking sees them as sentences. Disaster.
Three approaches that work:
Approach 1: Table-as-Text with Structure Preservation
Extract table to markdown or CSV
Keep column headers with every chunk
Add row numbers for reference
Include table title/caption
Approach 2: Table-as-Data with LLM Description
Extract table structure completely
Use an LLM to write a natural language description
Index both the description and the raw table
Return the raw table to the LLM when retrieved
Approach 3: Dual Indexing (Recommended)
Index table descriptions for retrieval
Store complete tables separately
Retrieve based on descriptions, return full tables
Best of both: searchable descriptions, complete data for LLM
Merged Cells
Financial reports love merged cells. Suppose “Q1-Q3 Revenue” spans three columns. Your table chunker breaks on column boundaries. Now you have three chunks with incomplete data.
Solution:
Detect merged cells during parsing
Unmerge them
Duplicate the original value into each individual cell
Now row-by-row chunking works properly
The Image Problem
Images contain information. Your text-based chunker ignores them. Bad news.
Three strategies:
Strategy 1: Image Captions Only
Extract image captions during parsing
Include captions in surrounding text chunks
Simplest but loses visual information
Strategy 2: Vision-Language Model Descriptions
Use GPT-4o, LLaVA, or similar to describe images
Store descriptions as text chunks
Index descriptions, link to original images
Retrieve description, return image to multimodal LLM
Strategy 3: Multimodal Embeddings
Use CLIP or similar for unified image-text embeddings
Index images and text together
Retrieve multimodal chunks
Requires multimodal LLM for generation
For production: Strategy 2. Descriptions are searchable, original images provide visual context, works with most LLMs.
The List Problem (Seriously, This Breaks More Than You’d Think)
Lists are deceptively simple. Until you chunk them wrong.
What breaks:
List Header: “Security Compliance Requirements”
- Item 1: Encrypt data at rest
[chunk boundary]
- Item 2: Implement MFA
- Item 3: Regular security audits
Now items 2 and 3 are orphaned. Nobody knows these are compliance requirements.
What works:
Chunk 1:
Security Compliance Requirements
- Item 1: Encrypt data at rest
Chunk 2:
Security Compliance Requirements
- Item 2: Implement MFA
Chunk 3:
Security Compliance Requirements
- Item 3: Regular security audits
Each list item gets the header. Each chunk makes sense alone.
Scaling to 10K+ Documents In Prod
Everything changes at scale. What works for 100 documents might not work for 10,000.
The Page-Level Chunking Revelation
Research shows page-level chunking is surprisingly effective at scale. One page = one chunk (or a few chunks if the page is huge).
Why this works:
Pages are already meaningful units
Authors structure pages with coherent information
Reduces total chunk count dramatically
Simplifies metadata management
When to use it: Large document collections (10K+) where processing speed matters and documents are multi-page (PDFs, reports, books).
The Metadata
At scale, metadata becomes critical. You need to filter before searching.
Essential metadata:
document_type: “financial_report”, “legal_contract”, “technical_manual”
date_created: ISO format timestamp
section_id: hierarchical identifier
parent_chunk_id: for hierarchical chunking
source_page: page number in original document
confidence_score: if using ML for structure detection
Why this matters: Searching 10,000 documents is slow. Searching “financial reports from Q4 2024” is fast.
Metadata lets you pre-filter to a manageable subset before doing vector similarity search.
The Hybrid Approach That Actually Works
Different document types need different strategies. At scale, you can’t use one strategy for everything.
Implementation:
1. Classify documents by type
- Financial: layout-aware + table processing
- Technical: layout-aware + hierarchical
- Legal: layout-aware + sliding window
- Research: semantic chunking
2. Route to appropriate chunking pipeline
3. Store with consistent metadata schema
4. Search with type-aware retrieval
This seems complex. It is. But it’s necessary at scale.
Chunk Size
Research consistently shows ~250 tokens (roughly 1000 characters) as a good starting point.
But—and this is important—document structure matters more than token count.
If your layout-aware chunker creates a 400-token chunk because that’s a complete section, that’s better than forcing it to 250 and breaking the section.
Use token limits as guidelines, not rules. Preserve semantic and structural integrity first.
How to Actually Evaluate Your Chunking Strategy
You can’t improve what you don’t measure. Here’s how to know if your chunking works.
The Metrics That Matter Here
Context Relevancy: Are retrieved chunks actually relevant to the query?
Measure: Human evaluation on sample queries. What percentage of retrieved chunks contain useful information?
Target: >80% relevancy on representative queries
Answer Faithfulness: Is the generated answer supported by retrieved chunks?
Measure: Check for hallucinations. Does the LLM invent facts not in the retrieved content?
Target: >90% faithfulness (anything less is dangerous)
Answer Completeness: Does the answer have all necessary information?
Measure: Compare against human-written answers. What’s missing?
Target: >85% completeness for critical use cases
The Test Set You Need
Create 50-100 test queries representing real use cases:
Easy queries (30%):
“What was Q3 revenue?”
“Who is the CEO?”
Direct fact lookups
Medium queries (50%):
“Why did revenue decline in Q3?”
“What are the security compliance requirements?”
Requires context from multiple chunks
Hard queries (20%):
“Compare Q3 performance across all product lines and explain regional variations”
“What are the legal implications of the liability clause exceptions?”
Requires synthesis across many chunks
The A/B Test Protocol
Don’t guess. Test.
Implement Strategy A (baseline: maybe fixed-size chunking)
Implement Strategy B (candidate: maybe layout-aware)
Run same test queries through both
Compare metrics
Human evaluation on disagreements
Important: Test on YOUR documents with YOUR queries. Benchmark results from papers don’t tell you what works for your use case.
The Red Flags That Mean You Need Better Chunking
Watch for these in user feedback:
“The answer was close but missed a key detail” → Context loss at chunk boundaries
“The system gave me a table but I don’t know what it means” → Table without context
“The answer contradicted itself” → Retrieved conflicting chunks without shared context
“The system couldn’t find information I know is there” → Poor chunk boundaries made content unretrievable
Each of these points to a chunking problem, not a retrieval problem.
The Decision Framework
Here’s how to actually decide what to implement.
Step 1: Understand Your Documents
What are you processing?
Mostly text (articles, books, reports)
Lots of tables (financial reports, data sheets)
Lots of images (technical manuals, scientific papers)
Highly structured (legal contracts, regulatory docs)
Mixed content (real-world documents)
Step 2: Understand Your Queries
What are people asking?
Simple fact lookup (”What is X?”)
Contextual questions (”Why did X happen?”)
Comparison questions (”How does X compare to Y?”)
Synthesis questions (”Explain the relationship between X, Y, and Z”)
Simple queries → simpler chunking might work
Complex queries → need sophisticated chunking
Step 3: Understand Your Constraints
What are your limits?
Processing time:
Need it fast? → Simpler chunking (recursive, layout-aware without heavy ML)
Can be slow? → Sophisticated chunking (agentic, semantic with fine-tuning)
Scale:
<1000 docs? → Any strategy works
1K-10K docs? → Need efficient processing, batch pipelines
10K docs? → Page-level chunking, distributed processing, metadata filtering
Accuracy requirements:
Low stakes (internal docs)? → Start simple, iterate based on feedback
High stakes (legal, medical)? → Invest in sophisticated chunking upfront
Step 4: The Decision Tree
For structured documents (PDFs, reports, manuals, contracts): → Start with layout-aware chunking
Add hierarchical metadata if documents have clear section structure Add specialized table/list handling if those are common Add vision processing if images are critical
For unstructured text (articles, books, chat logs): → Start with semantic chunking
Add recursive boundaries if you need more consistent chunk sizes Consider sliding window if context loss is an issue
For mission-critical applications (legal analysis, medical diagnosis): → Consider agentic chunking
Only if accuracy matters more than cost/speed Test thoroughly before production
For 10K+ documents: → Simplify where possible
Page-level chunking as baseline Hybrid approach with document classification Heavy investment in metadata and filtering
Step 5: Implementation Path
Week 1: Baseline
Implement simplest reasonable strategy (recursive or layout-aware basic)
Create test set of 50 queries
Measure baseline performance
Week 2: Iterate
Identify top failure modes from week 1
Implement targeted improvements (table handling, list processing, etc.)
Measure improvement
Week 3: Optimise
Fine-tune chunk sizes
Add metadata enrichment
Optimise for your specific queries
Week 4: Scale
Set up batch processing if needed
Implement monitoring
Plan for continuous improvement
The Bottom Line
Most RAG systems fail because of chunking, not because of embeddings or LLMs.
If you remember nothing else, remember this:
Structure matters. Documents have hierarchy. Use it.
Context matters. Tables without explanations are useless. Lists without headers are meaningless.
Different documents need different strategies. Financial reports aren’t blog posts.
At scale, simplicity wins. Page-level chunking beats complex strategies on 10K+ documents.
Measure everything. You can’t improve what you don’t measure.
Start with layout-aware chunking if you’re processing structured documents. It’s the single best improvement you can make to your RAG system.
Then iterate based on your specific failure modes. Add table handling. Add hierarchical metadata. Add specialized processing for lists.
But whatever you do, stop using fixed-size chunking in production. Your users deserve better.
Further Reading
Tools mentioned:
DeepDocDetection: github.com/deepdoctection/deepdoctection
Amazon Textract: aws.amazon.com/textract
Docling: Document preprocessing library
LlamaIndex: llamaindex.ai
LangChain: langchain.com
Research papers:
Search “semantic chunking RAG 2024” for latest benchmarks
Search “layout-aware document processing” for parsing techniques
Search “hierarchical retrieval RAG” for parent-child strategies
Implementation examples:
Look for “layout-aware document parsing for RAG” notebooks
AWS samples: amazon-archives/layout-aware-document-processing
Community implementations on GitHub
Have questions about chunking strategies for your specific use case? I’m always experimenting with new approaches and would love to hear what’s working (or not working) for you.
This piece gave me a few good ideas for chunking a Confluence website. I've been wondering how to preserve the context between linked Confluence pages. Thanks
How do you see overlapping between chunks fit into this? Its a bit of a clutch, but works really well to cover up chunking boundary issues.