
6 AI Agent Guides from Google, Anthropic, Microsoft, etc. Released This Week
Explained in 5 Mins With Miskies AI

The world of AI agents is moving at breakneck speed. This week alone, we saw major releases from Google, Microsoft, Anthropic, and leading research teams, each tackling a different piece of the AI agent puzzle.
But here’s the problem: these aren’t blog posts you can skim. They’re dense technical papers, lengthy documentation, and framework announcements that demand real attention.
That’s where Miskies AI comes in. We’ve taken six of the most important releases and transformed them into interactive, visual learning experiences. No walls of text. No jargon overload. Just clear explanations, interactive demos, and hands-on explorations that help you actually understand what’s happening in the agent ecosystem.
1. Google’s Vertex AI Agent Builder
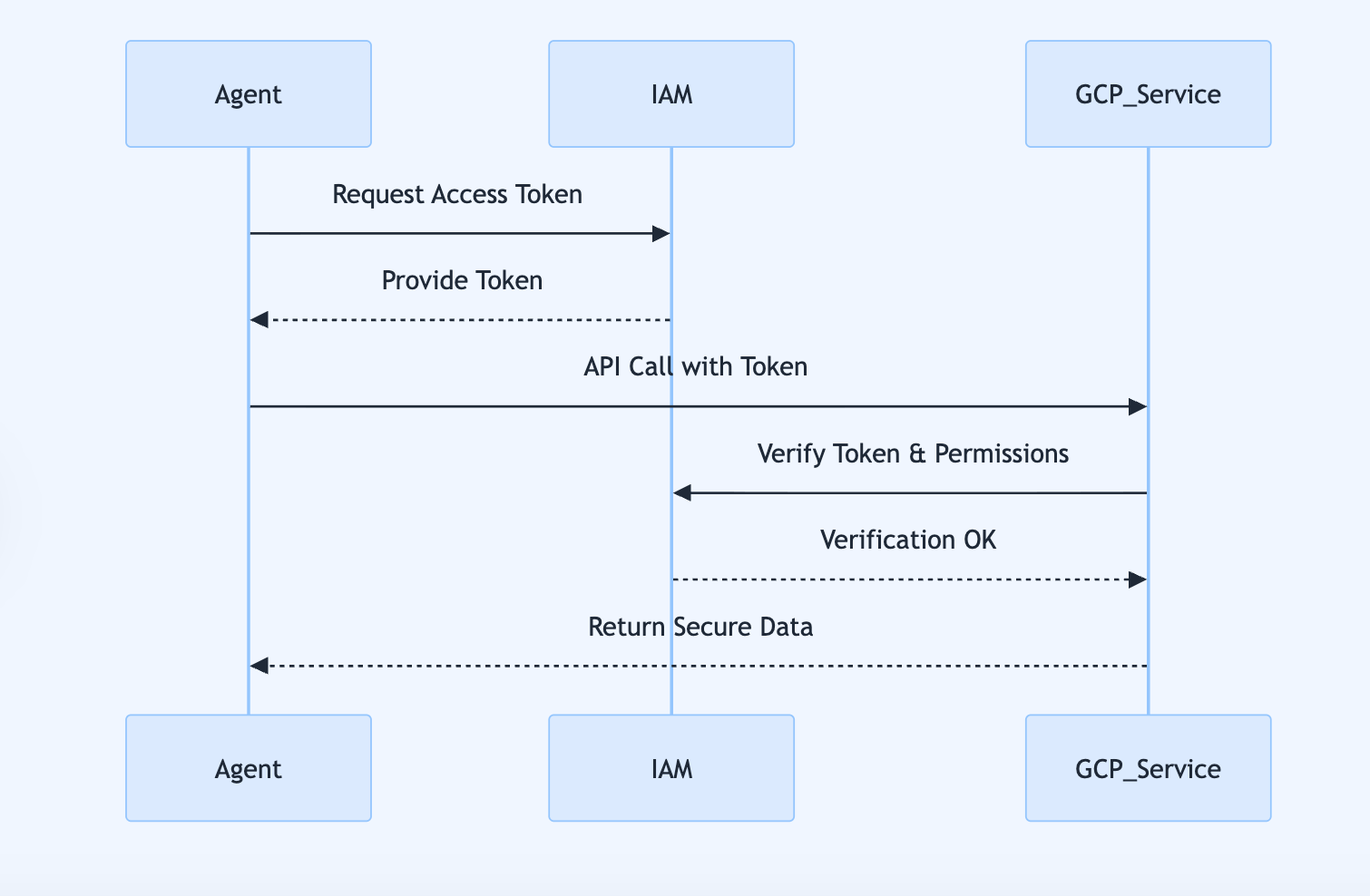
The diff between building a working AI agent prototype on your laptop and running it reliably in production at scale is where most projects die, and Agent Builder provides a unified platform that manages this entire lifecycle from development through deployment to governance.
Google organises the platform into three distinct pillars:
Build (featuring the Agent Development Kit with Python, Java, and Go support plus a plugin framework),
Scale (providing observability dashboards, traces for debugging, and evaluation layers with user simulators), and
Govern (offering native IAM identities for agents, Model Armor security, and Security Command Centre integrations).
The magic of the ADK is distilled into a single command—
adk deploy—that takes your locally developed agent and seamlessly deploys it to the Agent Engine runtime environment, eliminating the complex infrastructure work that traditionally blocks teams from shipping.
Companies like Color Health are using Agent Builder in production to build AI assistants that help screen women for breast cancer and schedule care, whilst PayPal uses the ADK to inspect agent interactions and manage multi-agent workflows for trusted agent-based payments at scale.
Open the full interactive guide here to explore Agent Builder’s three pillars with interactive diagrams, adjust context layer sliders to see token usage change in real-time, and understand why companies are finally bridging the prototype-production gap.
2. Microsoft’s Agent Lightning
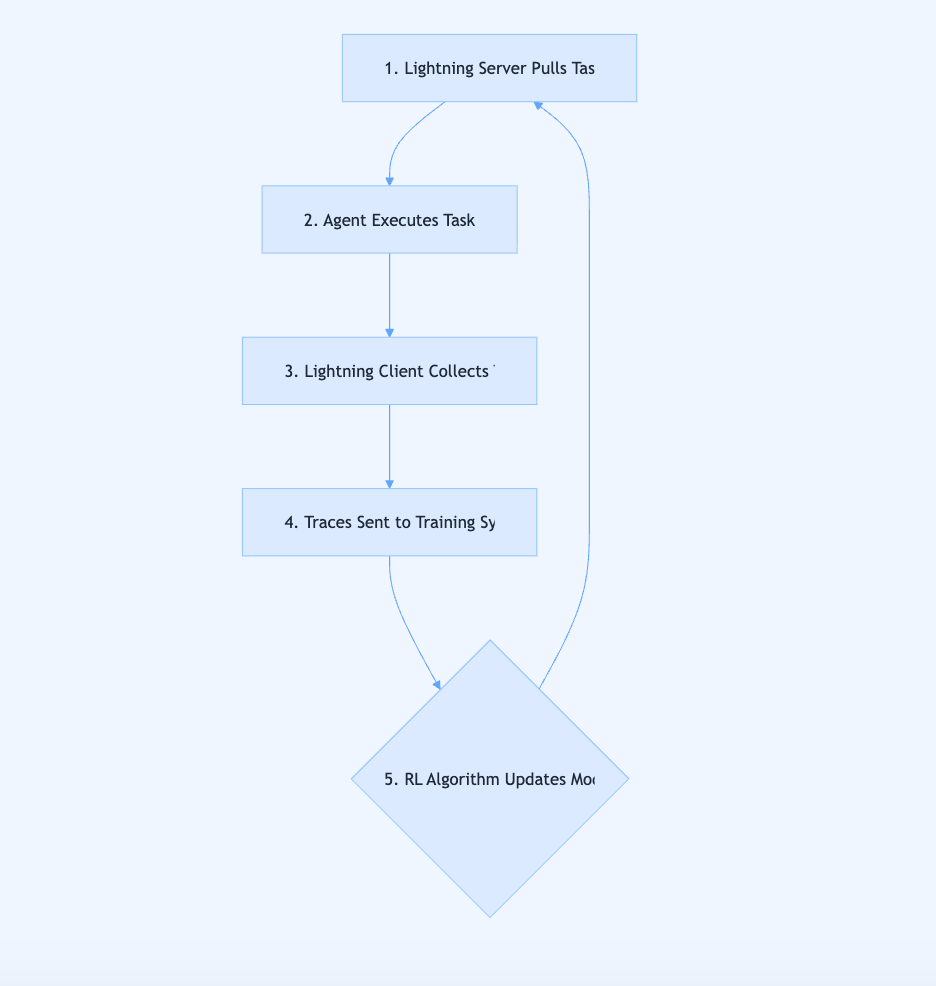
The AI agent ecosystem has evolved two completely separate worlds—agent development frameworks like LangChain and AutoGen that are brilliant at building complex workflows but have zero training capabilities, and model training frameworks that are powerful at optimisation but don’t understand the complexities of agent interactions.
Agent Lightning introduces a decoupled architecture with a Lightning Server and Lightning Client that act as a middle layer between your agent and its underlying model, which means your existing agent code remains completely unchanged whilst a separate system observes every interaction and optimises the model.
The framework operates non-intrusively by collecting interaction traces (state, action, reward, next state) as your agent runs normally, then feeding these traces into a reinforcement learning pipeline that progressively improves the model’s performance without requiring you to rewrite any of your agent logic.
Microsoft designed the system to tackle hard problems that plague traditional knowledge distillation, specifically handling distribution mismatch (where training data differs from inference data) and domain gaps (where a general teacher LLM needs to transfer knowledge to a specialised student SLM).
See the full interactive breakdown to see the RL training loop in action with step-by-step sequence diagrams, explore which optimisation method suits different goals with interactive components, and understand why this bridges a critical infrastructure gap.
3. Anthropic’s Context Engineering Guide
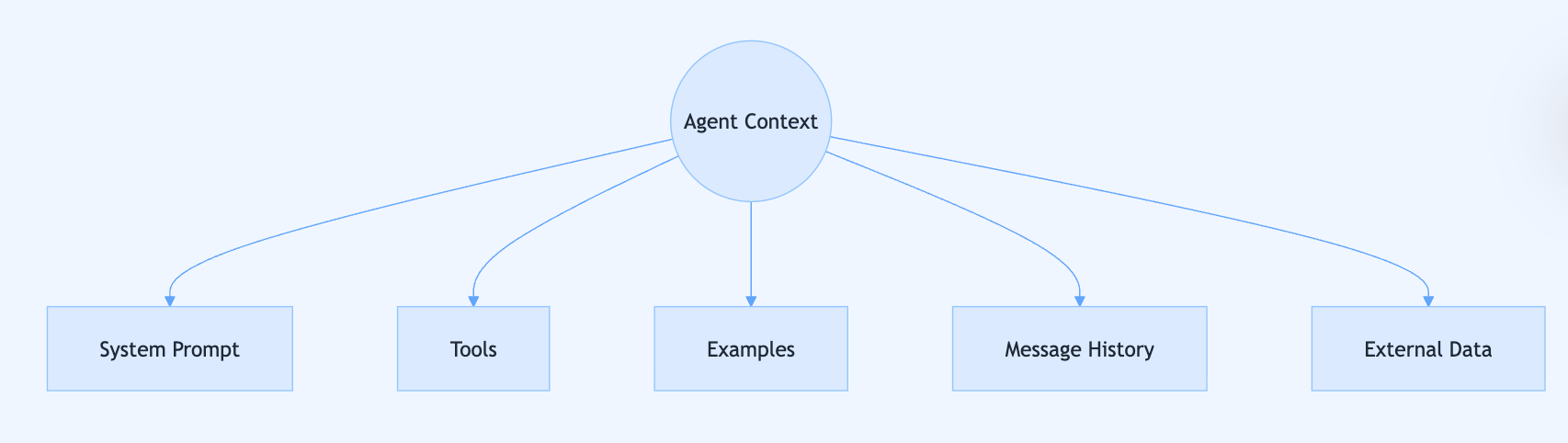
The field has moved beyond “prompt engineering” as the primary challenge—the new frontier is context engineering, which is the ongoing, iterative process of curating the entire set of information an agent uses across multiple turns, not just writing perfect initial instructions.
Context rot is a real, measurable phenomenon where LLMs progressively lose their ability to recall specific details as the context window fills up, stemming from the Transformer architecture’s fundamental limitation where every token must attend to every other token, creating an n² relationship that stretches attention thin.
The key principle that should guide all your decisions is treating context as a finite, precious resource (like RAM, not infinite storage) and finding the smallest possible set of high-signal tokens that maximises the likelihood of your desired outcome.
Effective system prompts must hit the Goldilocks Zone between being too vague (like “be a helpful assistant” which provides no concrete guidance) and too prescriptive (like hardcoded if-then rules that create brittle logic), instead providing strong heuristics and clear structure that guides behaviour flexibly.
Advanced strategies for long-horizon tasks include just-in-time agentic search (where agents progressively fetch information as needed rather than pre-loading massive files), compaction (summarising conversation history), structured note-taking (using external memory), and sub-agent architectures (delegating focused tasks to specialists).
Open the full interactive guide to explore prompt “altitude” with interactive sliders, simulate compaction aggressiveness, see sequence diagrams of just-in-time retrieval, and see the techniques that separate reliable agents from brittle ones.
4. Galileo’s Multi-Agent Systems Guide
Single, generalist agents often lose context when forced to juggle unrelated tasks like order tracking, billing queries, and product recommendations all at once, whereas specialised agents maintain a focused context for their specific domain, leading to fewer errors and better performance on each sub-task.
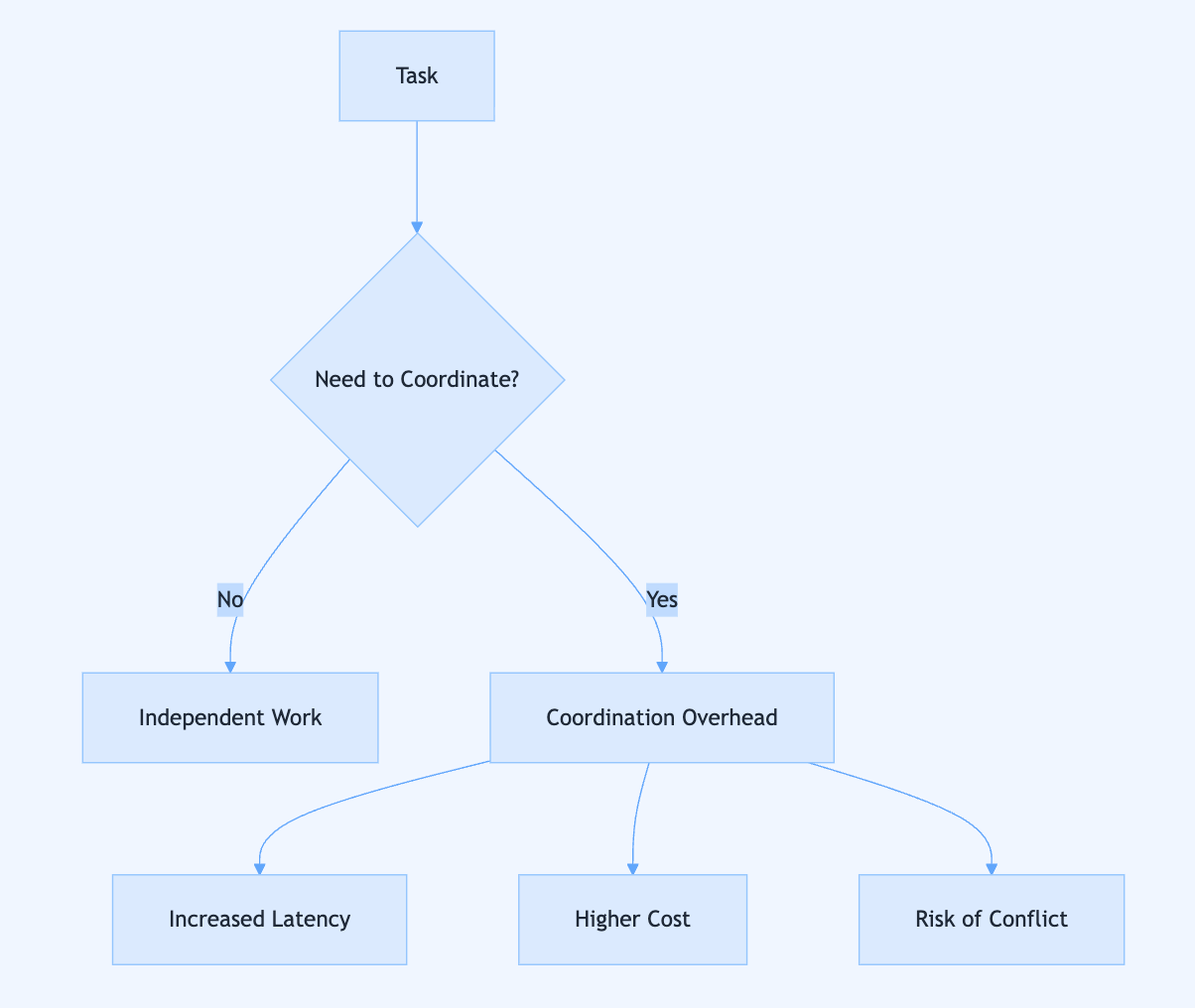
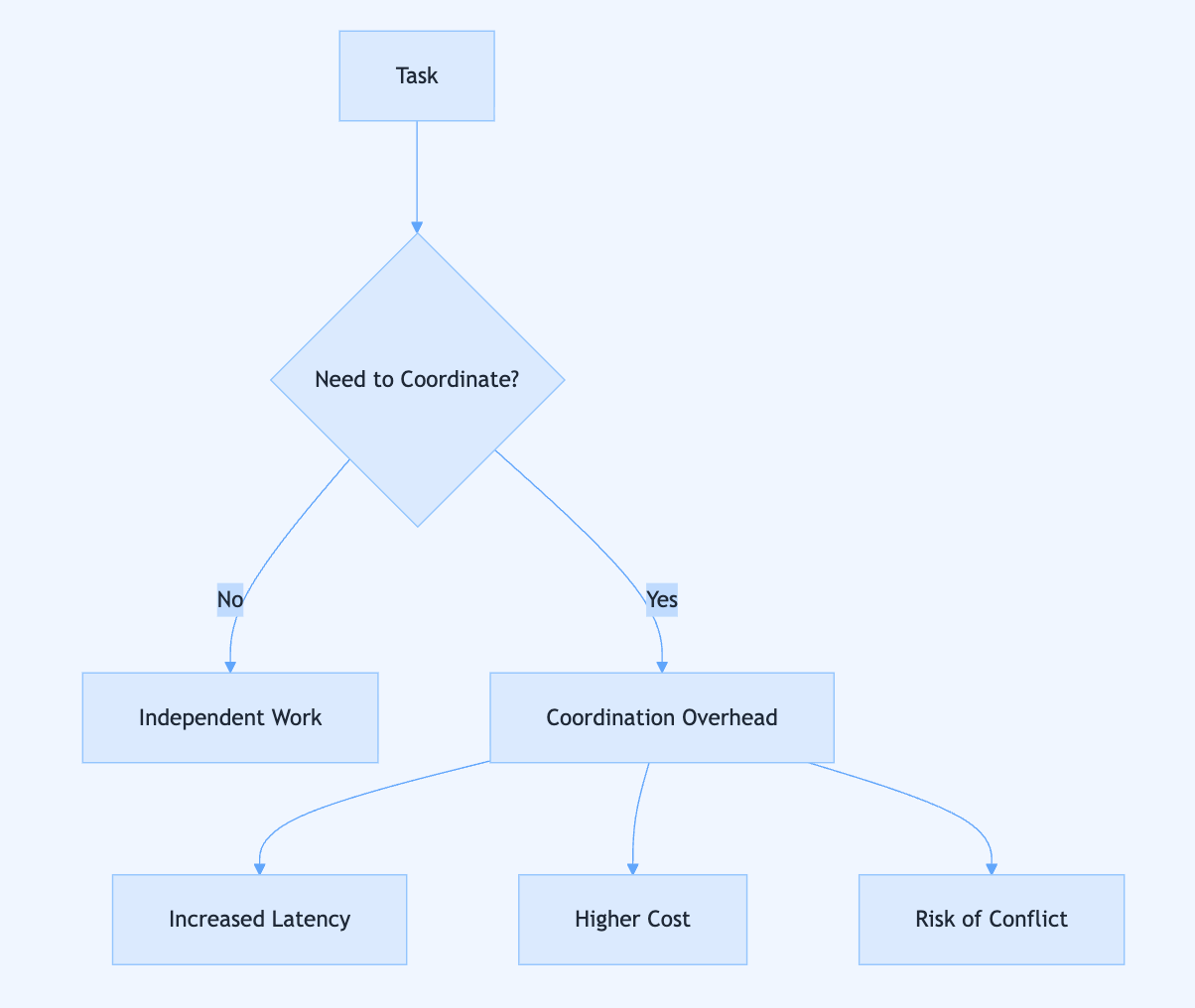
Whilst multi-agent systems offer powerful benefits like specialisation and parallelism, they introduce coordination overhead that grows exponentially rather than linearly—four agents require six communication channels, creating increased latency, higher costs, and new failure points that must be carefully managed.
The decision to use a multi-agent architecture isn’t obvious and requires weighing specific trade-offs: whether your sub-tasks are truly independent, whether you can absorb a 2-5x cost increase, and whether your latency tolerance is measured in seconds rather than milliseconds.
Four primary architectural patterns offer different trade-offs—centralised systems (orchestrator pattern) are easy to manage but create a single point of failure, decentralised systems (peer-to-peer) are more resilient but harder to coordinate, hierarchical systems create tree structures with supervisors and specialists, and hybrid systems mix these approaches.
See the full interactive breakdown to use the interactive decision framework with sliders, explore real production architectures from Color Health and PayPal, simulate observability metrics, and understand when multi-agent systems actually make sense.
5. Hugging Face’s Playbook On Building World-Class LLMs
Before burning millions in compute, you must answer a fundamental strategic question: do you actually need to train a new model, because “we have available compute” is just a resource not a goal, and “everyone else is doing it” is peer pressure not strategy.
The entire training process begins with systematic, small-scale ablations where you test each architectural decision (attention mechanism, positional encoding, activation function) at a manageable scale to get reliable signals before committing to a full run, a process called “derisking” that prevents expensive failures.
Long training runs are marathons filled with unexpected challenges that weren’t present in ablations—the SmolLM3 team faced throughput drops from disk latency, dataloader bugs that only manifested at scale, and mysterious performance cliffs that required systematic debugging to isolate and fix.
Post-training transforms a raw base model into a capable assistant through a multi-stage pipeline: supervised fine-tuning (SFT) teaches instruction-following and chat format, preference optimisation using techniques like DPO or KTO refines behaviour by learning from chosen versus rejected responses, and reinforcement learning optimises for specific outcomes like correctness or helpfulness.
6. The Comprehensive Survey of Small Language Models
Whilst the industry obsesses over ever-larger models, Small Language Models (SLMs) with parameters in the billions rather than hundreds of billions are proving that efficiency and capability aren’t mutually exclusive, offering deployment on resource-constrained devices like phones, preserving user privacy by keeping data on-device, responding in milliseconds rather than seconds, and enabling cheap customisation through fine-tuning.
Creating powerful SLMs typically starts with an existing LLM rather than training from scratch, using three primary compression techniques: pruning (removing less important parameters, either unstructured for maximum compression or structured for standard hardware compatibility), knowledge distillation (training a smaller student model to mimic a larger teacher), and quantisation (reducing numerical precision to save memory whilst minimising accuracy loss).
Enhancement strategies push SLM performance further through innovative training techniques, supervised fine-tuning with instruction tuning and preference optimisation, advanced distillation methods that handle distribution mismatch and domain gaps, performance-aware quantisation that carefully manages the accuracy-efficiency trade-off, and applying LLM techniques like RAG and MoE to smaller models.
The relationship between SLMs and LLMs isn’t purely competitive—SLMs can act as efficient, specialised assistants that improve LLM performance by verifying outputs as fast fact-checkers, calibrating confidence to help LLMs assess their own uncertainty, guarding safety by screening prompts and responses, and extracting prompts through reverse-engineering.
See the full interactive survey to experiment with quantisation bit depth and see precision changes, explore cloud-edge task allocation with interactive sliders, test your understanding of distillation challenges, and grasp why SLMs are essential for the next phase of AI deployment.
Why learn with Miskies AI
Miskies AI transforms any document or topic into visual, hands-on learning presentations. Upload your own technical papers, documentation, or guides at miskies.app and get an interactive breakdown in minutes.
Each of these topics is dense, important, and moving fast. Reading static documentation is one way to learn. But Miskies AI offers something better: interactive diagrams that show how systems connect, hands-on components where you can adjust parameters and see results change, quizzes that test your understanding, and visual breakdowns that make complex architectures clear.
Fascinating. While Agent Builder streamlines the dev-to-prod lifecycle brilliantly, I'm curious if its governance pillar adequately adressess ethical AI deployment challenges, especially for urban public policy contexts.